
Connect Sifter and MongoDB
Integrate Sifter with MongoDB to automate workflows, sync data between apps, and eliminate repetitive tasks with AI-powered automation.
Available events for Sifter and MongoDB
Supported Triggers & Actions
Everything you can automate between Sifter and MongoDB.
When this happensTriggers
A trigger is an event that starts a workflow.
New Issue Created
Runs when new issue created
Do thisActions
Action is the task that follows automatically within your Sifter integrations.
Create New Issue
Create new issue in project
List All Projects
Retrieve all projects
List Categories
Show project categories
List Project Assignees
Fetch assignees for a project
List Milestones
Skipped metadata generation as requested.

Learn how to build your first workflow
Follow a simple walkthrough to create, test, and launch your first automation.
- 1
Connect your apps
Link the apps you want to automate.
- 2
Configure your workflow
Set up triggers, actions, and map your data.
- 3
Test & publish
Test your workflow and publish it.
Trusted by Thousands. Recognized by the Best.
Recognized by leading review platforms and trusted by 10,000+ businesses worldwide.
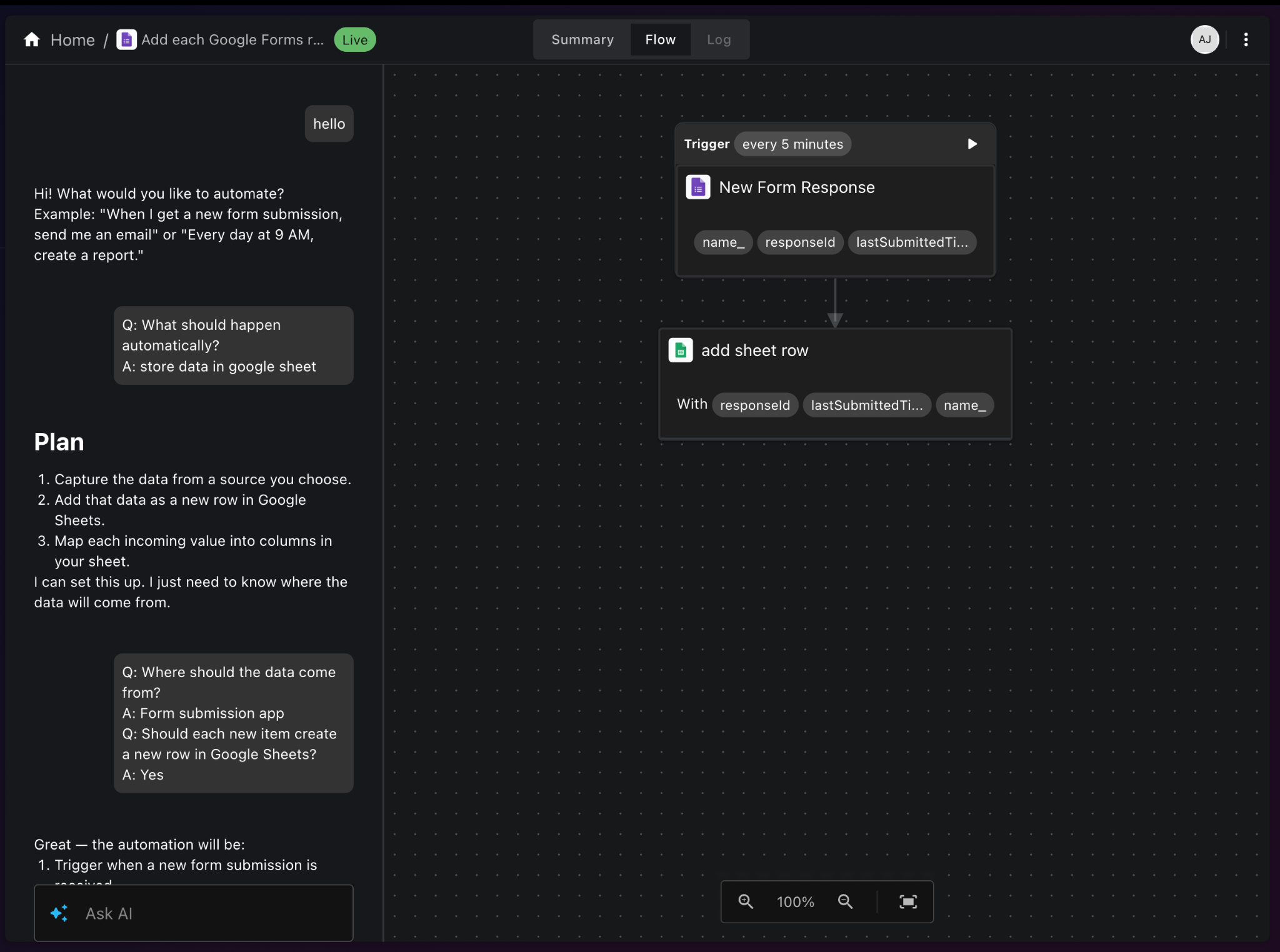
From idea to automation.
AI will build it for you
Just describe the task in plain English. viaSocket AI selects the right apps, builds the workflow, maps the fields, and prepares everything for review before you publish.
Learn More About Automation

How viaSocket Works | A Complete Guide
Discover viaSocket, an AI-powered workflow automation platform with 2,000+ integrations. Learn what it is, how it works, and how to set up no-code automated workflows.

5 Simple Automation Hacks to Make Your Team Free
Unlock your team's potential with 5 straightforward automation hacks designed to streamline processes and free up valuable time for more important work.
What is Workflow Automation - Definition, Importance & Benefits | A Complete Guide
Explore workflow automation: its definition, benefits, how it works, real-world examples, and how to automate with viaSocket.

What are Webhooks - Definition, Working, Usage & Examples | A Complete Guide
Discover what webhooks are, how they work, and when to use them. Compare push-based webhooks with APIs and polling, with practical examples and ViaSocket integration.
viaSocket Support
We're here to help
Instant answers
AI assistant available 24/7
Expert support
Connect with our specialists
Trusted & secure
Your data is safe with us
Start automating Sifter and MongoDB free
No credit card required. Set up your first workflow in minutes.
Similar apps
About MongoDB
MongoDB is a leading NoSQL database platform that provides a flexible and scalable solution for managing large volumes of data. It is designed to handle unstructured data and offers high performance, high availability, and easy scalability.
Learn moreFrequently Asked Questions
Sign up for a free viaSocket account, then authorize both your Sifter and MongoDB accounts. From there, pick a trigger in one app and an action in the other. Your first workflow can be live in under five minutes.
Yes. viaSocket uses instant triggers where available, so data moves between Sifter and MongoDB as soon as the event happens. Scheduled polling triggers run at a maximum interval of 15 minutes.
Yes. You can map specific fields, apply filters to skip records that do not match your conditions, and transform values before they reach MongoDB. No coding required.
Yes. You can set up a workflow where Sifter triggers actions in MongoDB, and a separate workflow where MongoDB triggers actions in Sifter. Both run independently and in real time.
viaSocket logs every run so you can see exactly what succeeded and what failed. Failed tasks can be retried from the dashboard without re-configuring the workflow.
Yes, there is a free plan that covers basic workflows between Sifter and MongoDB. Paid plans unlock higher task limits, faster polling, and advanced features like multi-step workflows and conditional logic.
No. The entire Sifter and MongoDB integration is built through a visual, point-and-click interface. Code blocks are available if you want them, but they are never required.
